system-design-primer-update
Real world architectures
Articles on how real world systems are designed.
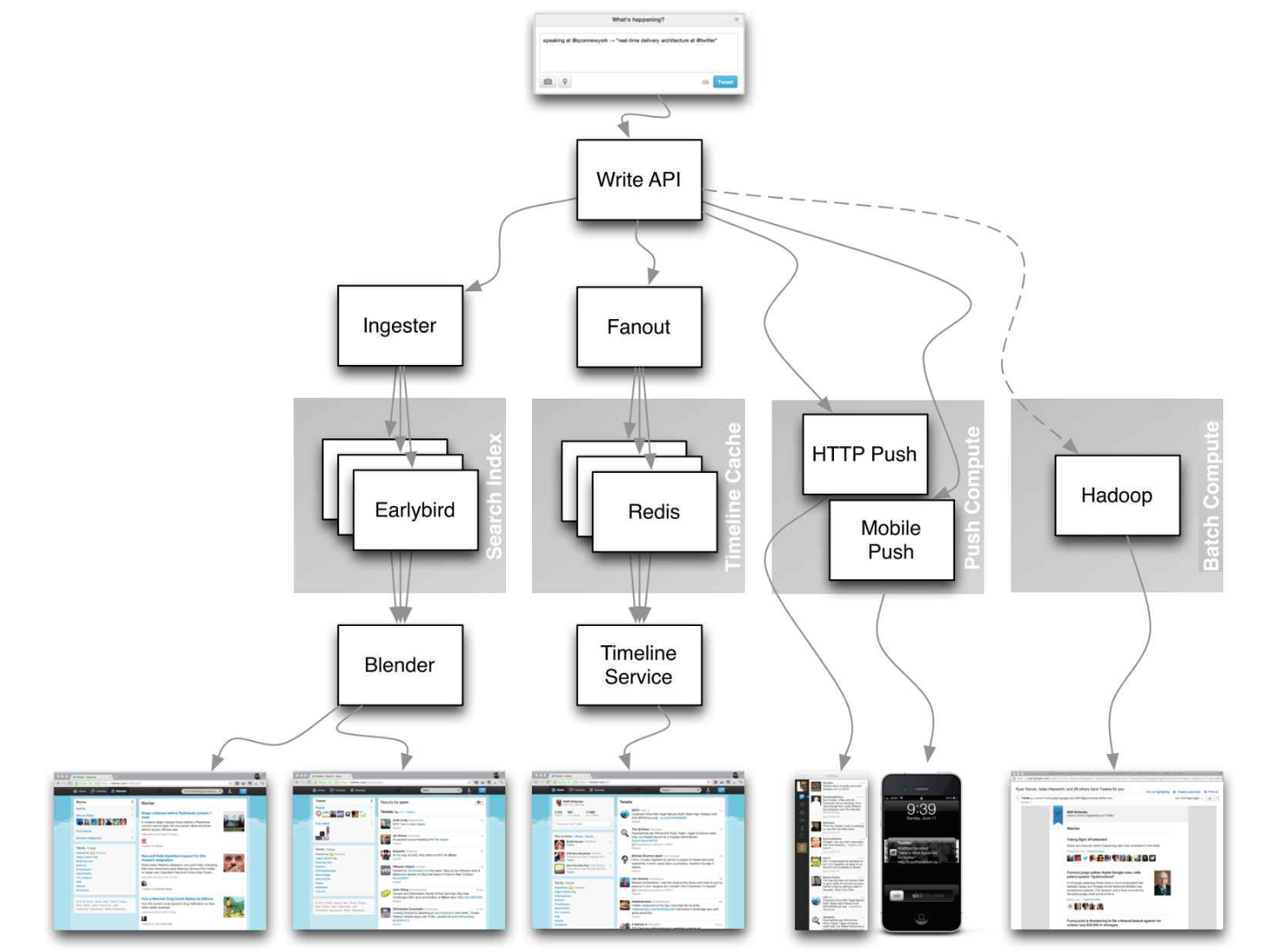
<a href=https://www.infoq.com/presentations/Twitter-Timeline-Scalability>Source: Twitter timelines at scale</a>
Don’t focus on nitty gritty details for the following articles, instead:
- Identify shared principles, common technologies, and patterns within these articles
- Study what problems are solved by each component, where it works, where it doesn’t
- Review the lessons learned
| Type | System | Reference(s) |
|---|---|---|
| Data processing | MapReduce - Distributed data processing from Google | research.google.com |
| Data processing | Spark - Distributed data processing from Databricks | slideshare.net |
| Data processing | Storm - Distributed data processing from Twitter | slideshare.net |
| Data store | Bigtable - Distributed column-oriented database from Google | harvard.edu |
| Data store | HBase - Open source implementation of Bigtable | slideshare.net |
| Data store | Cassandra - Distributed column-oriented database from Facebook | slideshare.net |
| Data store | DynamoDB - Document-oriented database from Amazon | harvard.edu |
| Data store | MongoDB - Document-oriented database | slideshare.net |
| Data store | Spanner - Globally-distributed database from Google | research.google.com |
| Data store | Memcached - Distributed memory caching system | slideshare.net |
| Data store | Redis - Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) - Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| Misc | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Misc | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Misc | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| Misc | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Contribute |
Company architectures
Company engineering blogs
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Source(s) and further reading
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo: