system-design-primer-update
Asynchronism
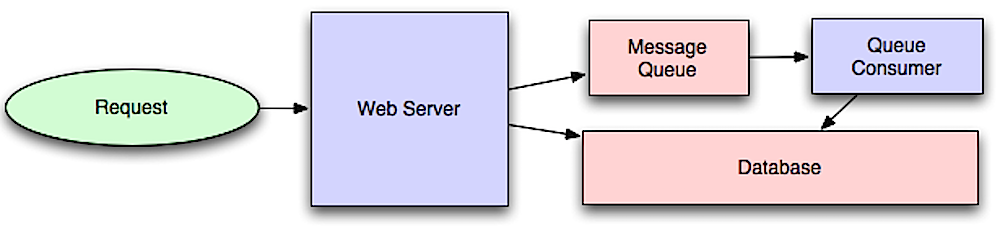
<a href=http://lethain.com/introduction-to-architecting-systems-for-scale/#platform_layer>Source: Intro to architecting systems for scale</a>
Asynchronous workflows help reduce request times for expensive operations that would otherwise be performed in-line. They can also help by doing time-consuming work in advance, such as periodic aggregation of data.
Message queues
Message queues receive, hold, and deliver messages. If an operation is too slow to perform inline, you can use a message queue with the following workflow:
- An application publishes a job to the queue, then notifies the user of job status
- A worker picks up the job from the queue, processes it, then signals the job is complete
The user is not blocked and the job is processed in the background. During this time, the client might optionally do a small amount of processing to make it seem like the task has completed. For example, if posting a tweet, the tweet could be instantly posted to your timeline, but it could take some time before your tweet is actually delivered to all of your followers.
Redis is useful as a simple message broker but messages can be lost.
RabbitMQ is popular but requires you to adapt to the ‘AMQP’ protocol and manage your own nodes.
Amazon SQS is hosted but can have high latency and has the possibility of messages being delivered twice.
Task queues
Tasks queues receive tasks and their related data, runs them, then delivers their results. They can support scheduling and can be used to run computationally-intensive jobs in the background.
Celery has support for scheduling and primarily has python support.
Back pressure
If queues start to grow significantly, the queue size can become larger than memory, resulting in cache misses, disk reads, and even slower performance. Back pressure can help by limiting the queue size, thereby maintaining a high throughput rate and good response times for jobs already in the queue. Once the queue fills up, clients get a server busy or HTTP 503 status code to try again later. Clients can retry the request at a later time, perhaps with exponential backoff.
Disadvantage(s): asynchronism
- Use cases such as inexpensive calculations and realtime workflows might be better suited for synchronous operations, as introducing queues can add delays and complexity.
Source(s) and further reading
- It’s all a numbers game
- Applying back pressure when overloaded
- Little’s law
- What is the difference between a message queue and a task queue?
Communication
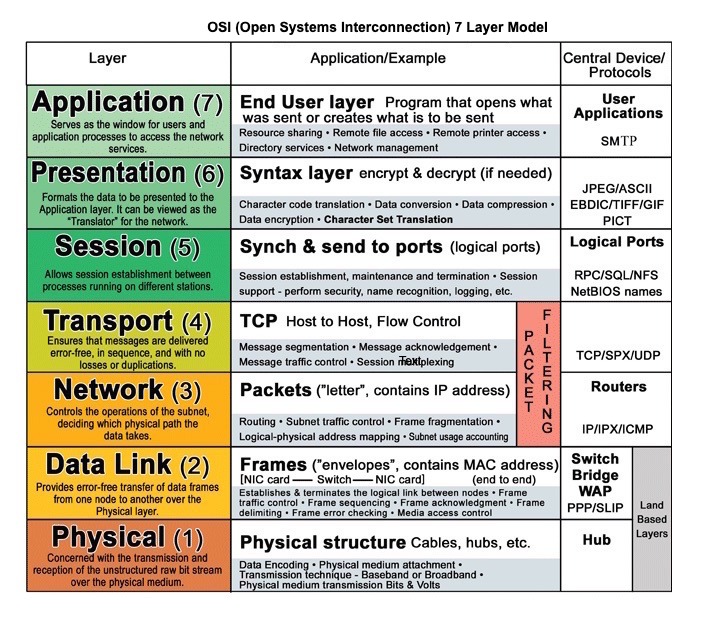
<a href=http://www.escotal.com/osilayer.html>Source: OSI 7 layer model</a>
Hypertext transfer protocol (HTTP)
HTTP is a method for encoding and transporting data between a client and a server. It is a request/response protocol: clients issue requests and servers issue responses with relevant content and completion status info about the request. HTTP is self-contained, allowing requests and responses to flow through many intermediate routers and servers that perform load balancing, caching, encryption, and compression.
A basic HTTP request consists of a verb (method) and a resource (endpoint). Below are common HTTP verbs:
| Verb | Description | Idempotent* | Safe | Cacheable |
|---|---|---|---|---|
| GET | Reads a resource | Yes | Yes | Yes |
| POST | Creates a resource or trigger a process that handles data | No | No | Yes if response contains freshness info |
| PUT | Creates or replace a resource | Yes | No | No |
| PATCH | Partially updates a resource | No | No | Yes if response contains freshness info |
| DELETE | Deletes a resource | Yes | No | No |
*Can be called many times without different outcomes.
HTTP is an application layer protocol relying on lower-level protocols such as TCP and UDP.
Source(s) and further reading: HTTP
Transmission control protocol (TCP)
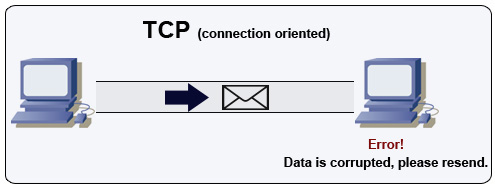
<a href=http://www.wildbunny.co.uk/blog/2012/10/09/how-to-make-a-multi-player-game-part-1/>Source: How to make a multiplayer game</a>
TCP is a connection-oriented protocol over an IP network. Connection is established and terminated using a handshake. All packets sent are guaranteed to reach the destination in the original order and without corruption through:
- Sequence numbers and checksum fields for each packet
- Acknowledgement packets and automatic retransmission
If the sender does not receive a correct response, it will resend the packets. If there are multiple timeouts, the connection is dropped. TCP also implements flow control and congestion control. These guarantees cause delays and generally result in less efficient transmission than UDP.
To ensure high throughput, web servers can keep a large number of TCP connections open, resulting in high memory usage. It can be expensive to have a large number of open connections between web server threads and say, a memcached server. Connection pooling can help in addition to switching to UDP where applicable.
TCP is useful for applications that require high reliability but are less time critical. Some examples include web servers, database info, SMTP, FTP, and SSH.
Use TCP over UDP when:
- You need all of the data to arrive intact
- You want to automatically make a best estimate use of the network throughput
User datagram protocol (UDP)
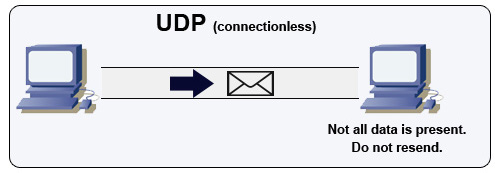
<a href=http://www.wildbunny.co.uk/blog/2012/10/09/how-to-make-a-multi-player-game-part-1/>Source: How to make a multiplayer game</a>
UDP is connectionless. Datagrams (analogous to packets) are guaranteed only at the datagram level. Datagrams might reach their destination out of order or not at all. UDP does not support congestion control. Without the guarantees that TCP support, UDP is generally more efficient.
UDP can broadcast, sending datagrams to all devices on the subnet. This is useful with DHCP because the client has not yet received an IP address, thus preventing a way for TCP to stream without the IP address.
UDP is less reliable but works well in real time use cases such as VoIP, video chat, streaming, and realtime multiplayer games.
Use UDP over TCP when:
- You need the lowest latency
- Late data is worse than loss of data
- You want to implement your own error correction
Source(s) and further reading: TCP and UDP
- Networking for game programming
- Key differences between TCP and UDP protocols
- Difference between TCP and UDP
- Transmission control protocol
- User datagram protocol
- Scaling memcache at Facebook
Remote procedure call (RPC)

<a href=http://www.puncsky.com/blog/2016-02-13-crack-the-system-design-interview>Source: Crack the system design interview</a>
In an RPC, a client causes a procedure to execute on a different address space, usually a remote server. The procedure is coded as if it were a local procedure call, abstracting away the details of how to communicate with the server from the client program. Remote calls are usually slower and less reliable than local calls so it is helpful to distinguish RPC calls from local calls. Popular RPC frameworks include Protobuf, Thrift, and Avro.
RPC is a request-response protocol:
- Client program - Calls the client stub procedure. The parameters are pushed onto the stack like a local procedure call.
- Client stub procedure - Marshals (packs) procedure id and arguments into a request message.
- Client communication module - OS sends the message from the client to the server.
- Server communication module - OS passes the incoming packets to the server stub procedure.
- Server stub procedure - Unmarshalls the results, calls the server procedure matching the procedure id and passes the given arguments.
- The server response repeats the steps above in reverse order.
Sample RPC calls:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC is focused on exposing behaviors. RPCs are often used for performance reasons with internal communications, as you can hand-craft native calls to better fit your use cases.
Choose a native library (aka SDK) when:
- You know your target platform.
- You want to control how your “logic” is accessed.
- You want to control how error control happens off your library.
- Performance and end user experience is your primary concern.
HTTP APIs following REST tend to be used more often for public APIs.
Disadvantage(s): RPC
- RPC clients become tightly coupled to the service implementation.
- A new API must be defined for every new operation or use case.
- It can be difficult to debug RPC.
- You might not be able to leverage existing technologies out of the box. For example, it might require additional effort to ensure RPC calls are properly cached on caching servers such as Squid.
Representational state transfer (REST)
REST is an architectural style enforcing a client/server model where the client acts on a set of resources managed by the server. The server provides a representation of resources and actions that can either manipulate or get a new representation of resources. All communication must be stateless and cacheable.
There are four qualities of a RESTful interface:
- Identify resources (URI in HTTP) - use the same URI regardless of any operation.
- Change with representations (Verbs in HTTP) - use verbs, headers, and body.
- Self-descriptive error message (status response in HTTP) - Use status codes, don’t reinvent the wheel.
- HATEOAS (HTML interface for HTTP) - your web service should be fully accessible in a browser.
Sample REST calls:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
REST is focused on exposing data. It minimizes the coupling between client/server and is often used for public HTTP APIs. REST uses a more generic and uniform method of exposing resources through URIs, representation through headers, and actions through verbs such as GET, POST, PUT, DELETE, and PATCH. Being stateless, REST is great for horizontal scaling and partitioning.
Disadvantage(s): REST
- With REST being focused on exposing data, it might not be a good fit if resources are not naturally organized or accessed in a simple hierarchy. For example, returning all updated records from the past hour matching a particular set of events is not easily expressed as a path. With REST, it is likely to be implemented with a combination of URI path, query parameters, and possibly the request body.
- REST typically relies on a few verbs (GET, POST, PUT, DELETE, and PATCH) which sometimes doesn’t fit your use case. For example, moving expired documents to the archive folder might not cleanly fit within these verbs.
- Fetching complicated resources with nested hierarchies requires multiple round trips between the client and server to render single views, e.g. fetching content of a blog entry and the comments on that entry. For mobile applications operating in variable network conditions, these multiple roundtrips are highly undesirable.
- Over time, more fields might be added to an API response and older clients will receive all new data fields, even those that they do not need, as a result, it bloats the payload size and leads to larger latencies.
RPC and REST calls comparison
| Operation | RPC | REST |
|---|---|---|
| Signup | POST /signup | POST /persons |
| Resign | POST /resign { “personid”: “1234” } |
DELETE /persons/1234 |
| Read a person | GET /readPerson?personid=1234 | GET /persons/1234 |
| Read a person’s items list | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Add an item to a person’s items | POST /addItemToUsersItemsList { “personid”: “1234”; “itemid”: “456” } |
POST /persons/1234/items { “itemid”: “456” } |
| Update an item | POST /modifyItem { “itemid”: “456”; “key”: “value” } |
PUT /items/456 { “key”: “value” } |
| Delete an item | POST /removeItem { “itemid”: “456” } |
DELETE /items/456 |
<a href=https://apihandyman.io/do-you-really-know-why-you-prefer-rest-over-rpc/>Source: Do you really know why you prefer REST over RPC</a>
Source(s) and further reading: REST and RPC
- Do you really know why you prefer REST over RPC
- When are RPC-ish approaches more appropriate than REST?
- REST vs JSON-RPC
- Debunking the myths of RPC and REST
- What are the drawbacks of using REST
- Crack the system design interview
- Thrift
- Why REST for internal use and not RPC
Security
This section could use some updates. Consider contributing!
Security is a broad topic. Unless you have considerable experience, a security background, or are applying for a position that requires knowledge of security, you probably won’t need to know more than the basics:
- Encrypt in transit and at rest.
- Sanitize all user inputs or any input parameters exposed to user to prevent XSS and SQL injection.
- Use parameterized queries to prevent SQL injection.
- Use the principle of least privilege.
Source(s) and further reading
Appendix
You’ll sometimes be asked to do ‘back-of-the-envelope’ estimates. For example, you might need to determine how long it will take to generate 100 image thumbnails from disk or how much memory a data structure will take. The Powers of two table and Latency numbers every programmer should know are handy references.
Powers of two table
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Source(s) and further reading
Latency numbers every programmer should know
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Handy metrics based on numbers above:
- Read sequentially from HDD at 30 MB/s
- Read sequentially from 1 Gbps Ethernet at 100 MB/s
- Read sequentially from SSD at 1 GB/s
- Read sequentially from main memory at 4 GB/s
- 6-7 world-wide round trips per second
- 2,000 round trips per second within a data center
Latency numbers visualized
Source(s) and further reading
- Latency numbers every programmer should know - 1
- Latency numbers every programmer should know - 2
- Designs, lessons, and advice from building large distributed systems
- Software Engineering Advice from Building Large-Scale Distributed Systems
Additional system design interview questions
Common system design interview questions, with links to resources on how to solve each.
| Question | Reference(s) |
|---|---|
| Design a file sync service like Dropbox | youtube.com |
| Design a search engine like Google | queue.acm.org stackexchange.com ardendertat.com stanford.edu |
| Design a scalable web crawler like Google | quora.com |
| Design Google docs | code.google.com neil.fraser.name |
| Design a key-value store like Redis | slideshare.net |
| Design a cache system like Memcached | slideshare.net |
| Design a recommendation system like Amazon’s | hulu.com ijcai13.org |
| Design a tinyurl system like Bitly | n00tc0d3r.blogspot.com |
| Design a chat app like WhatsApp | highscalability.com |
| Design a picture sharing system like Instagram | highscalability.com highscalability.com |
| Design the Facebook news feed function | quora.com quora.com slideshare.net |
| Design the Facebook timeline function | facebook.com highscalability.com |
| Design the Facebook chat function | erlang-factory.com facebook.com |
| Design a graph search function like Facebook’s | facebook.com facebook.com facebook.com |
| Design a content delivery network like CloudFlare | figshare.com |
| Design a trending topic system like Twitter’s | michael-noll.com snikolov .wordpress.com |
| Design a random ID generation system | blog.twitter.com github.com |
| Return the top k requests during a time interval | cs.ucsb.edu wpi.edu |
| Design a system that serves data from multiple data centers | highscalability.com |
| Design an online multiplayer card game | indieflashblog.com buildnewgames.com |
| Design a garbage collection system | stuffwithstuff.com washington.edu |
| Design an API rate limiter | https://stripe.com/blog/ |
| Design a Stock Exchange (like NASDAQ or Binance) | Jane Street Golang Implementation Go Implementation |
| Add a system design question | Contribute |
Real world architectures
Articles on how real world systems are designed.
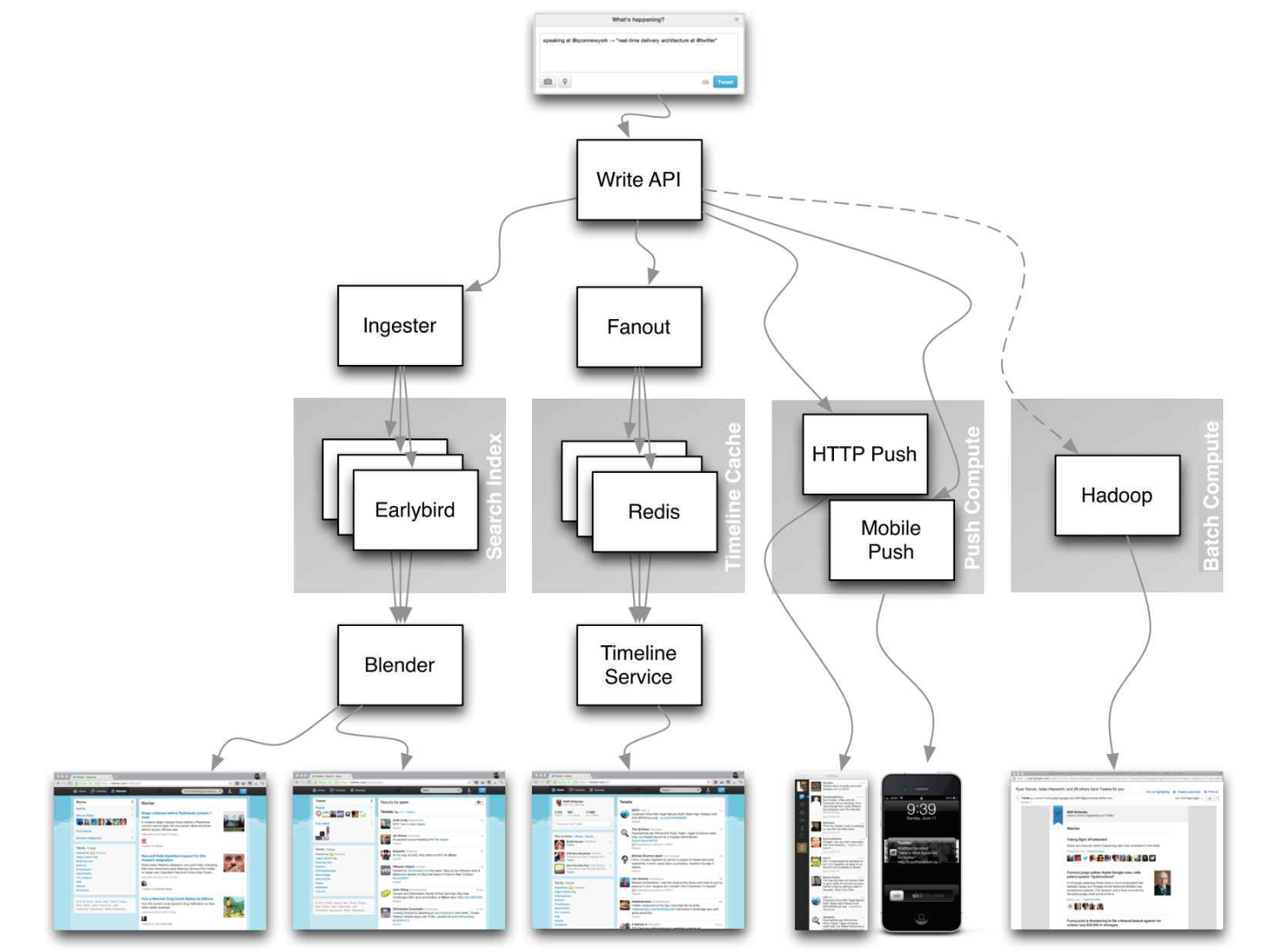
<a href=https://www.infoq.com/presentations/Twitter-Timeline-Scalability>Source: Twitter timelines at scale</a>
Don’t focus on nitty gritty details for the following articles, instead:
- Identify shared principles, common technologies, and patterns within these articles
- Study what problems are solved by each component, where it works, where it doesn’t
- Review the lessons learned
| Type | System | Reference(s) |
|---|---|---|
| Data processing | MapReduce - Distributed data processing from Google | research.google.com |
| Data processing | Spark - Distributed data processing from Databricks | slideshare.net |
| Data processing | Storm - Distributed data processing from Twitter | slideshare.net |
| Data store | Bigtable - Distributed column-oriented database from Google | harvard.edu |
| Data store | HBase - Open source implementation of Bigtable | slideshare.net |
| Data store | Cassandra - Distributed column-oriented database from Facebook | slideshare.net |
| Data store | DynamoDB - Document-oriented database from Amazon | harvard.edu |
| Data store | MongoDB - Document-oriented database | slideshare.net |
| Data store | Spanner - Globally-distributed database from Google | research.google.com |
| Data store | Memcached - Distributed memory caching system | slideshare.net |
| Data store | Redis - Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) - Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| Misc | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Misc | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Misc | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| Misc | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Contribute |
Company architectures
Company engineering blogs
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Source(s) and further reading
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Under development
Interested in adding a section or helping complete one in-progress? Contribute!
- Distributed computing with MapReduce
- Consistent hashing
- Scatter gather
- Contribute
Credits
Credits and sources are provided throughout this repo.
Special thanks to:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Contact info
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
License
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/